
CATVis: Context-Aware Thought Visualization
Tariq Mehmood*, Hamza Ahmad*, Muhammad Haroon Shakeel, Murtaza Taj (* contributed equally)
Abstract:
EEG-based brain-computer interfaces (BCIs) have shown promise in various applications, such as motor imagery and cognitive state monitoring. However, decoding visual representations from EEG signals remains a significant challenge due to their complex and noisy nature. We thus propose a novel 5-stage framework for decoding visual representations from EEG signals: (1) an EEG encoder for concept classification, (2) cross-modal alignment of EEG and text embeddings in CLIP feature space, (3) caption refinement via re-ranking, (4) weighted interpolation of concept and caption embeddings for richer semantics, and (5) image generation using a pre-trained Stable Diffusion model. We enable context-aware EEG-to-image generation through cross-modal alignment and re-ranking. Experimental results demonstrate that our method generates high-quality images aligned with visual stimuli, outperforming SOTA approaches by 27.08% in Classification Accuracy, 15.21% in Generation Accuracy and reducing Fréchet Inception Distance by 36.61%, indicating superior semantic alignment and image quality.
Methodology:
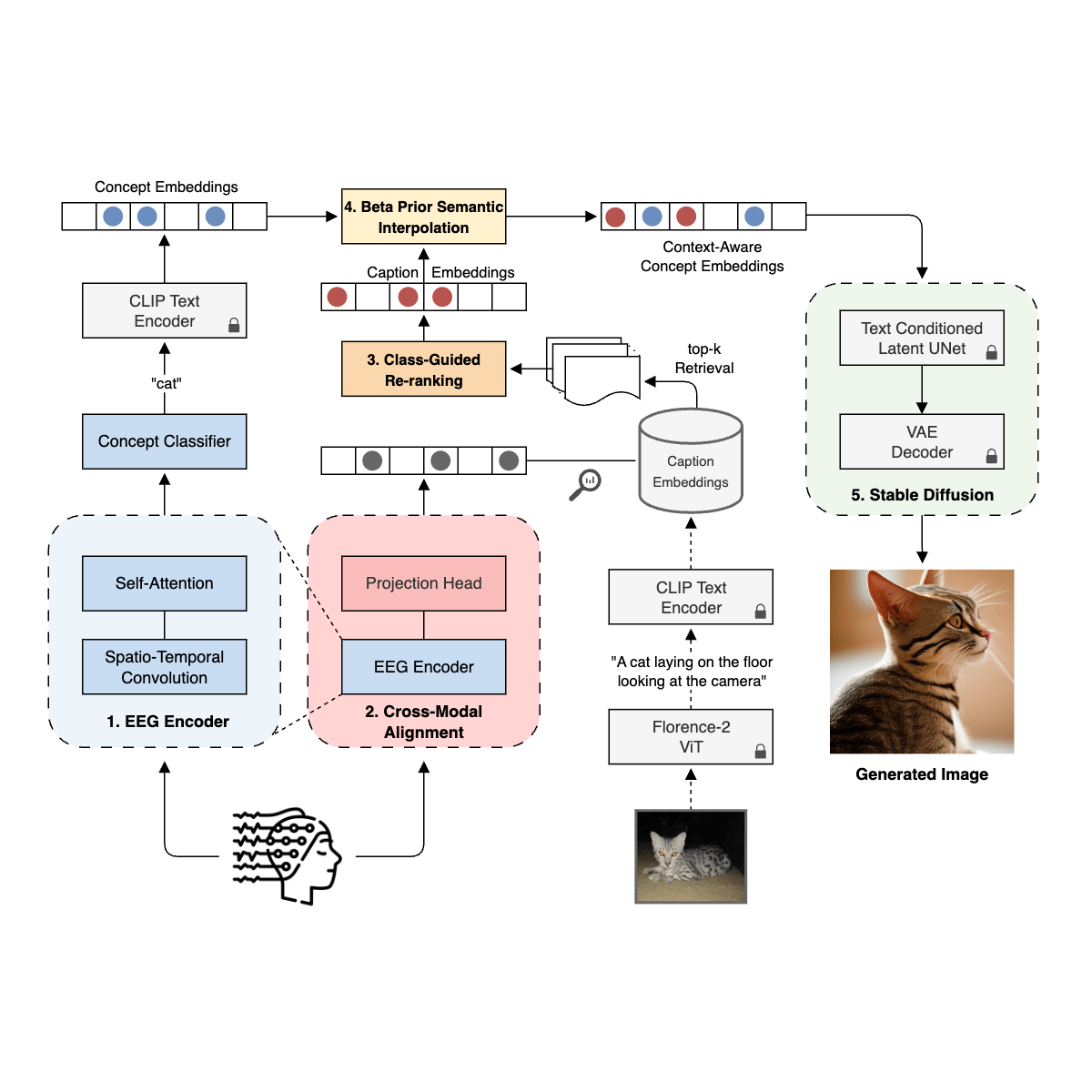
Our framework, CATVis, reconstructs visual representations from EEG via a five-stage pipeline that balances concept-level predictions with richer contextual descriptions.
- EEG Encoder. A Conformer-based encoder captures spatio-temporal EEG patterns for concept classification.
- Cross-modal Alignment. EEG embeddings are projected into CLIP’s joint feature space and aligned with caption embeddings using contrastive learning.
- Caption Refinement. Top candidate captions are retrieved and re-ranked using class-guided similarity to better match the subject’s perception.
- Semantic Interpolation. Predicted class embeddings and the re-ranked caption embedding are interpolated to form a semantically rich conditioning vector.
- Image Generation. A pre-trained Stable Diffusion model generates images conditioned on the fused embeddings, producing photorealistic reconstructions that reflect both object class and contextual details.
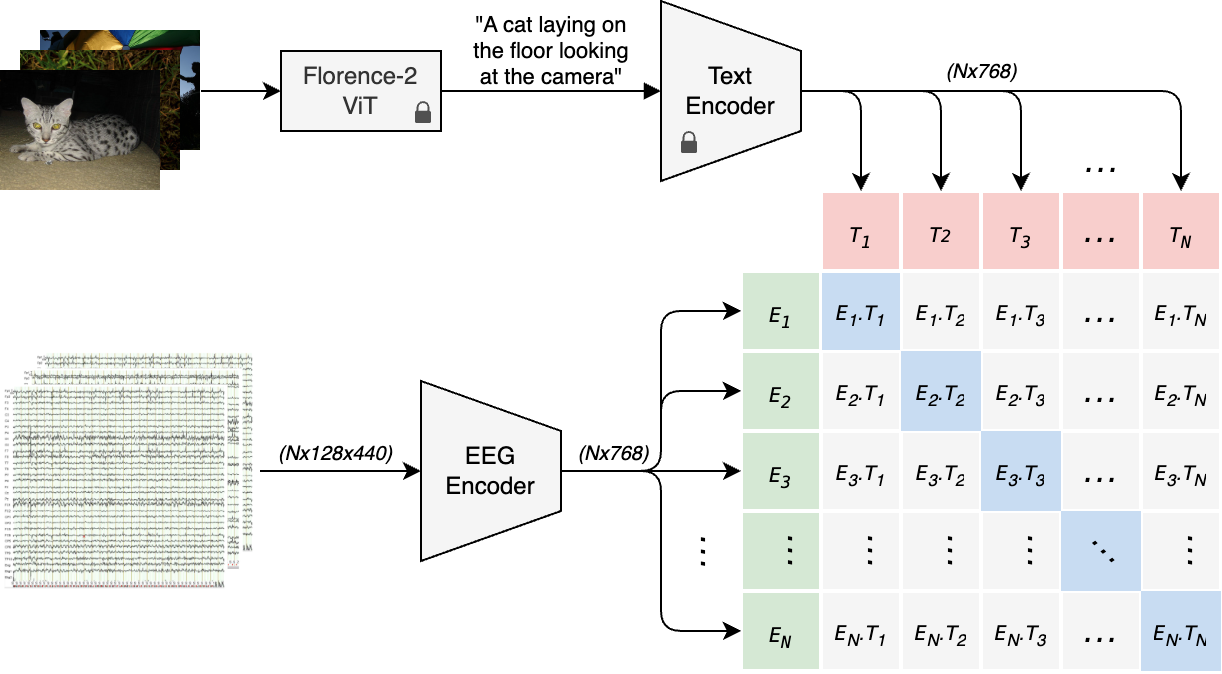
This design enables context-aware EEG-to-image generation and improves semantic alignment between neural activity and generated visuals.
Results:
Our framework achieves significant improvements in EEG-based visual reconstruction. Compared to state-of-the-art methods, CATVis boosts classification accuracy by 27.08%, improves generation accuracy by 15.21%, and reduces Fréchet Inception Distance by 36.61%, resulting in higher semantic alignment and image quality. The qualitative samples visually affirm our quantitative results. The generated images not only resemble the visual stimuli in terms of object identity but also capture surrounding context and attributes, such as shape, color, and spatial composition. This level of detail, rarely observed in prior EEG-to-image works, validates the core premise of our framework: that context-aware thought visualization is achievable through careful alignment of EEG semantics and generative priors.

Resources:
Text Reference:
T. Mehmood, H. Ahmad, M. H. Shakeel, and M. Taj, "CATVis: Context-Aware Thought Visualization," in Proc. of the Int. Conf. on Medical Image Computing and Computer Assisted Intervention (MICCAI), 2025
Bibtex Reference:
@inproceedings{CATVisMICCAI2025,
author={T. Mehmood, H. Ahmad, M. H. Shakeel, and M. Taj},
title={CATVis: Context-Aware Thought Visualization},
booktitle={Proc. of the Int. Conf. on Medical Image Computing and Computer Assisted Intervention (MICCAI)},
year={2025},
}



